Introduction
Clustering algorithms are a type of unsupervised machine learning algorithm. Since unsupervised learning uses unlabeled data, clustering algorithms differ from supervised learning by dividing datasets into several natural groups based on the similarity of their characteristics.
Types of Clustering Algorithms
Clustering is a branch of unsupervised machine learning that encompasses several techniques. Some of the most prominent clustering algorithms are listed below:
- K-Means Clustering
- Hierarchical Clustering
- Fuzzy C-Means Clustering
#1 K-Means Clustering
K-Means Clustering is one of the simplest and most frequently used unsupervised learning algorithms. In this method, "K" represents the targeted number of clusters within the dataset. A "centroid" is the imaginary or real location representing the center of a cluster, where a cluster refers to a group of data points with shared similarities.
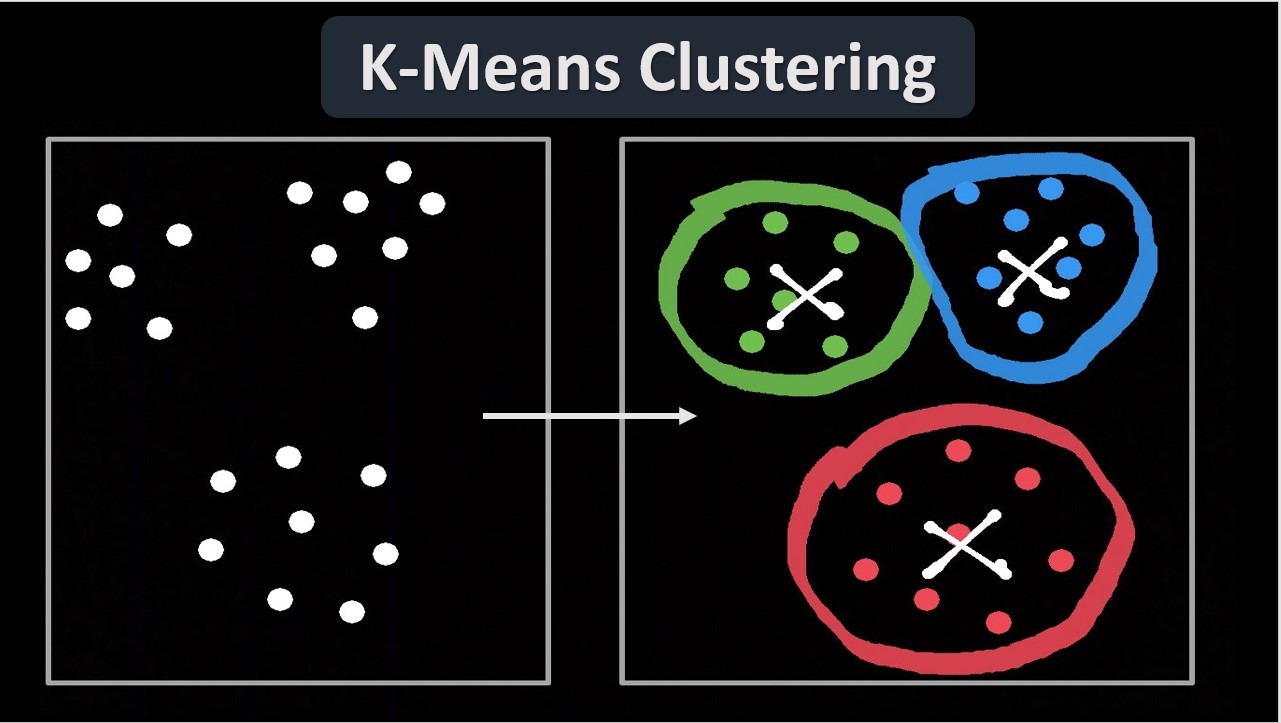
The algorithm begins by selecting random initial points to serve as the starting centroids for the clusters. It then performs iterative calculations to optimize the locations of these centroids until the data points are grouped effectively.
#2 Hierarchical Clustering
Hierarchical Clustering Analysis is a technique that organizes similar data points or objects into groups called clusters. In this approach, we initially treat each object as a separate cluster. The algorithm then computes the distances between clusters and merges those that are most similar.
There are two primary methods to perform hierarchical clustering:
- Agglomerative Clustering: Also known as AGNES (Agglomerative Nesting), this is a "bottom-up" approach. The process starts with each data point as an individual cluster (leaf). In each subsequent step, the two most similar clusters are combined into a larger cluster (node). This continues until all data points are members of a single large cluster.
- Divisive Clustering: Also known as DIANA (Divisive Analysis), this is a "top-down" approach. This algorithm follows the inverse order of AGNES. It begins with all data points in one root cluster and recursively splits them until each data point becomes an individual, single-element cluster.
#3 Fuzzy C-Means Clustering Algorithm
Fuzzy C-Means Clustering is an unsupervised machine learning algorithm that allows a single piece of data to belong to more than one cluster. In layman's terms, a data point is a member of its neighboring clusters based on a specific degree of belonging known as a "membership value." This method was developed by Dunn in 1973 and improved by Bezdek in 1981. It is most commonly used in pattern recognition.
Applications of Clustering
- Recommendation engines
- Market and Customer Segmentation
- Social Network Analysis
- Search Result Grouping
- Biological Data Analysis
We will discuss these concepts in greater detail in upcoming blogs.
Powered by Froala Editor



