What is Data Science?
Data science is an interdisciplinary field that combines three domains: computer science, business/domain expertise, and mathematics & statistics. While other skills are involved, most are covered by these three disciplines. Some sources describe data science as the integration of specialized statistics, data analytics (or business analytics), and machine learning. This relationship is illustrated in the following Venn diagram.
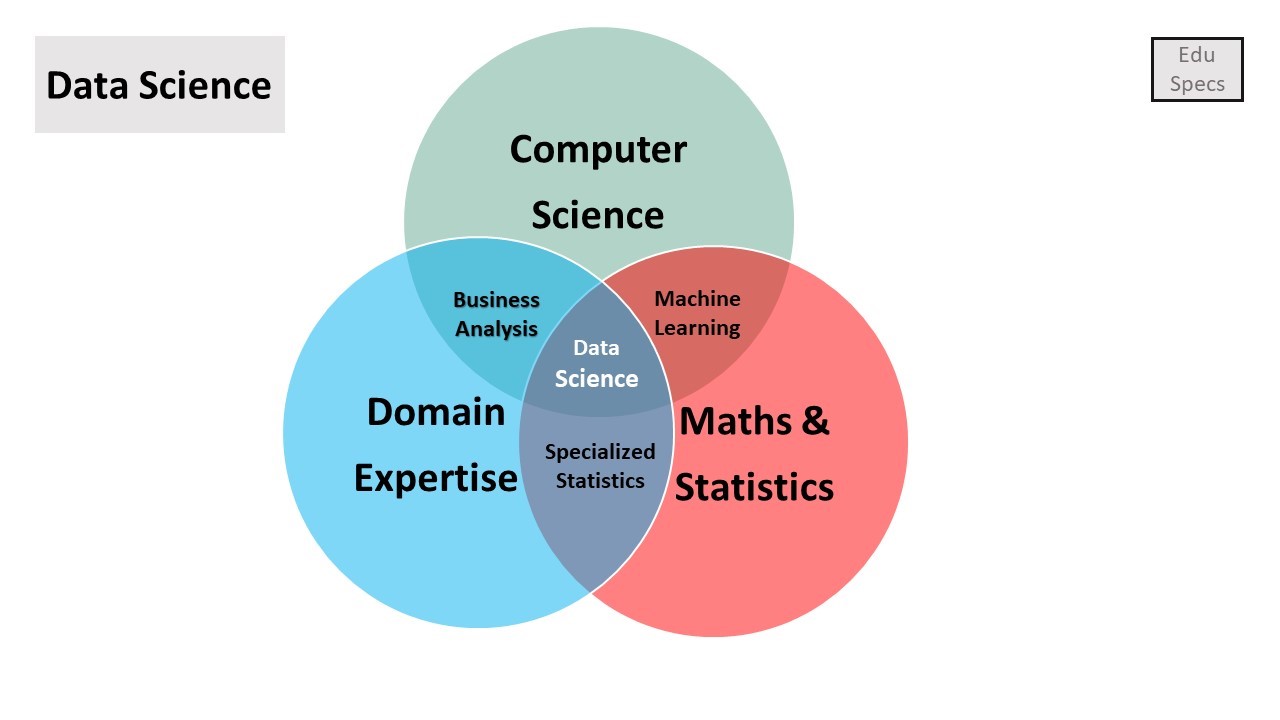
Data science has numerous applications across various fields, such as Amazon and Netflix recommendation engines, recognition systems (image, text, video, audio, and face detection), fraud detection, predictive modeling, insights visualization, forecasting (weather, sales, and revenue), and spam email detection.
Data Science Life Cycle

1. Problem Understanding
Whenever we start a project within a company or team, we must have a solid understanding of the relevant industry. This could be financial services, information technology (IT), investment banking (IB), fintech, or healthcare. Market understanding is mandatory because it is essential for identifying specific objectives and problems. To provide value, we must be familiar with the industry's unique challenges.
Problem understanding is the initial stage of the data science life cycle. Without it, all subsequent insights are useless; you must understand the purpose behind your data analytics, predictions, or forecasting.
For example, if you are working as a data scientist at Netflix (an OTT platform), you might be given a dataset to compare your company’s performance against competitors. You may need to analyze market share, revenue, and hidden data patterns. Success in this task requires being familiar with the industry's competitive landscape and core problems.
2. Data Understanding
Data understanding is the step where you perform data collection from various sources, such as surveys, corporate datasets, research websites, or third-party providers. It is crucial to ensure that the collected data is relevant to your specific objectives.
After Data Collection, we proceed to Exploratory Data Analysis (EDA). In this phase, we identify features, correlations between variables, data types (numerical vs. categorical), and data structures. This is often done using visualization tools such as Matplotlib, Seaborn, Tableau, Power BI, or R.
3. Data Preparation
Following the data understanding step, the next phase in the Data Science Life Cycle is Data Preparation. It mainly consists of three steps:
1. Data Wrangling: This involves selecting relevant data, integrating datasets through merging, cleaning the data, and handling missing values (by either removing them or imputing them with relevant values). It also involves treating erroneous data and identifying/handling outliers.
2. Feature Selection: This is the process of selecting a subset of relevant input features from the dataset. This process primarily focuses on removing non-informative or redundant predictors to improve model performance.
There are two main categories of feature selection:
Unsupervised Learning: Does not use a target variable (e.g., Correlation analysis).
- Correlation
Supervised Learning: Uses the target variable to guide selection.
- Wrapper: Searches for well-performing subsets of features by training models.
- Filter: Selects subsets of features based on their statistical relationship with the target.
- Intrinsic: Algorithms that perform automatic feature selection during the training process.
3. Feature Engineering:
Feature engineering is the process of transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved accuracy on unseen data.
By combining feature selection and feature engineering, we transform raw data into refined datasets that help us perform more effective descriptive and predictive analytics.
4. Algorithm Selection
The algorithm selection and evaluation process is the heart of data analysis. This involves choosing the appropriate statistical or machine learning algorithm based on the input and output data types identified during previous stages. Depending on the problem, you might choose regression, clustering, or classification models.
After selecting a model, you must tune its hyperparameters to achieve the desired performance level.
5. Evaluation
As the final step of the machine learning cycle and the penultimate step of the data science life cycle, Evaluation is the process of measuring a model's accuracy, efficiency, and relevance to the original problem.
While accuracy refers to how well the model performs on the prepared dataset, the relevance step ensures that the insights generated actually answer the business problem. We must also balance performance and generalizability to ensure the model is not biased or overfit to the training data.
6. Deployment
Many people assume that modeling and evaluation are the final stages, but the life cycle concludes with Deployment. In data science, deployment refers to integrating the model into a production environment where it can process new data. This allows the organization to make practical, data-driven business decisions in real time.
It is vital to maintain accuracy in the preceding steps (Understanding, Preparation, and Selection), as even small errors in the early stages can lead to significant failures during the deployment phase.
Powered by Froala Editor



